chibica (チビカ)
chibica (チビカ) 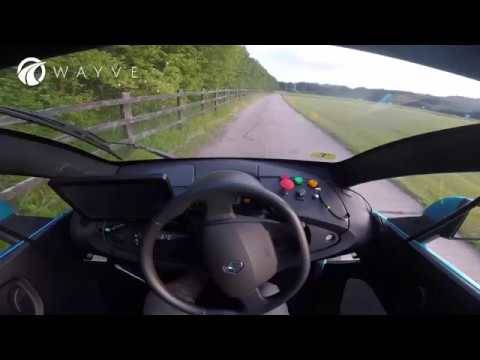
ケンブリッジ大学工学部の出身者によって創業されたWayveというスタートアップ企業が、人工知能(AI)を使って自動運転車に20分で技術を教え込ませる事を可能にしたとしています。同社の公式サイトを見ていると、ハッタリではないのがまざまざと分かります。本当にSFの世界。シュール・リアリスティックな感覚にすら襲われます。
覚え込ませているのは1台のコンピュータとカメラのみ
via www.youtube.com
ハンドルはあるものの、ドライバーが余り触ることもなく、快適とも言うべき速度で疾走しているのが分かります。そのプロセスにも驚かされます。ちなみにWaymoやUberでも同種の車は制作していますが、複数のセンサーや、特別にカスタマイズ化したハードウェアを装着しているのに対し、Wayveでは覚え込ませているのは1台のコンピュータとカメラのみ。特殊な操作を何ら必要としていないのですから。
なお、工学の世界では、こうした教えこみのことを「強化学習」(reinforcement learning)と呼ぶのだそうですが、その最初の実践となったのは同社だとのことです。
鍵を握っているのはAI。4層から成る畳み込みニューラルネットワークによって、積載したリアルタイム画像処理に特化したプロセッサであるGPU(グラフィックス・プロセッシング・ユニット)で全てをやってのけるのだそうです。つまり、クラウド・コンピューティングによる接続や、マップの事前のローディングなどが不要なのです。ちなみに、これで自動運転の初期レベル5に該当するとのことです。
積載されたWayveのAIが、あらゆる状況下でも運転可能となるまでには、まだまだ多くの作業が必要とされています。 しかし、こうした自動運転車には何万ドルものハードウェアが必要になるという考えを打ち砕こうとしているのが、同社の驚異的とも言えるディープ・ラーニングとなるのです。
Wayveによると、使われているアルゴリズムは、今後よりスマートになるだろうとしています
人間のドライバーの質の95%に相当する運転アルゴリズムを使って、初期の段階の自動運転車が大量に運用されている様子を御想像下さい。 こうしたシステムは、デモンストレーション・ビデオで映し出された、ランダムに初期化されたモデルのようにふらつくこともなく、信号機や迂回路、交差点などに対応することは、ほぼ可能です。 丸一日かけて運転させ、人による安全なオンライン運転を施して改善すれば、おそらくシステムは96%まで改善されます。 1週間後なら98%ですし、1ヶ月後は99%でしょう。 数ヶ月後には、システムはスーパー・ヒューマンとも言うべき存在となり、多くの安全な運転によるフィードバックによって、恩恵を受けているかもしれません。
「本当に、そうなっているのかも」と思わされますね。
「初めて自転車に乗った時のような感じです」と同社
同社では、自社の公式ブログで、「幼少時代、初めて自転車に乗った時のことを思い出して下さい」と、このディープ・ラーニングについて説明しています。
「興奮と不安を抱えながら、大人に後押しされながら乗り、よろめいたりこけたりしながらも、数時間後には公園や草原を走っていたでしょう?」と。まして、この自動運転の学習には、3Dマップも、長々と暗記させられた交通法規も不要だとしています。
同社が採用したのはディープ強化学習アルゴリズム(Deep Deterministic Policy Gradients=DDPG)。車線の運転は、これによるタスクに従うことで解決しました。 1台の単眼カメラ画像によって、 探査(exploration)、最適化(optimisation)、評価(evaluation)の3つのプロセスを繰り返させるようにもしています。

via wayve.ai
実際の危険な状況下でも使えるように様々なシミュレーションを繰り返したのは言うまでもありません。こうした探査運転を「エピソード」として区分してディープ・ラーニングさせ、どれだけ少ない「エピソード」で道路を運行放棄に従って走行可能とさせるかが課題だったそうです。
まとめ:「自動運転車の性能を、十分なレベルにまで向上させたい」
なお、こうしたラーニングに当っては、自転車による初めての走行体験の他に、料理の仕方の学習方法も参考になるのではないかと、研究の対象にしていたのだそうです。研究そのものに柔軟な思考が求められるのですね。
人工知能を作り出して有名になったディープマインド社があります。Wayveでは、ディープマインドの強化学習の手法が、囲碁やチェス、コンピュータゲームなど、多くのゲームで人間を凌ぐパフォーマンスを達成したことで「現実の世界、特に自動運転車でも同様の達成が可能である」と考えているそうです。
注目すべき重要な点として、ディープマインド社によるアタリの再生アルゴリズムは、タスク解決までに何百万もの試行を必要としたことをあげています。一方「我々は一貫して20回以下の試行で車線遵守を学ばせた。ここは注目に値すると思う」としています。ちょっと自慢が入っているかな?
ともあれ、ロボット・インテリジェンスを構築するのに、大規模なモデルや派手なセンサーや、無限のデータは不要だというのが同社の哲学だそうです。「我々が必要とするのは、上で示されたビデオのように、迅速かつ効率的に学ぶ賢いトレーニングプロセスである」と、言い切っています。
清々しさを感じさせる社是ですね。どうかブレることなく、達成してほしいものです!
出典:
https://thenextweb.com/artificial-intelligence/2018/07/06/this-startup-can-teach-a-car-how-to-drive-itself-in-20-minutes/
https://wayve.ai/blog/learning-to-drive-in-a-day-with-reinforcement-learning
]]>
https://thenextweb.com/artificial-intelligence/2018/07/06/this-startup-can-teach-a-car-how-to-drive-itself-in-20-minutes/
https://wayve.ai/blog/learning-to-drive-in-a-day-with-reinforcement-learning